
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 로그 데이터
- 자바스크립트
- function
- 아이비시트
- 자바
- 인텔리J
- athena
- Java
- aws lambda
- Git
- ibsheet
- 환경 구성
- aws S3
- s3
- 자바8
- JavaScript
- #jQuery
- 환경구성
- AWS Glue
- AWS SQS
- intellij
- AWS Athena
- jQuery
- 카이호스트만
- Study
- naver smartEditor
- AWS
- Log
- db
- java8
- Today
- Total
목록Glue (2)
애매한 잡학사전
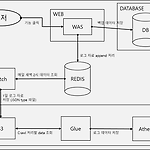 AWS를 이용한 대용량 Log 데이터 처리하기 시행착오 정리
AWS를 이용한 대용량 Log 데이터 처리하기 시행착오 정리
1. 개요 - 상황 1) 사용자가 Web에서 클릭한 모든 기능에 대해 데이터베이스에 저장 2) 하루 평균 40만 ~ 50만 건의 데이터가 저장 3) 현재까지 약 4억 건의 데이터가 저장 되어 있음 4) DBMS에서 쿼리 실행 시 Web 사용자가 많을 경우 DB lock 현상이 발생 5) 운영 DB와 Data log 데이블이 한 서버에 있어서 log 데이터 조회 시 DB 커넥션 증가 : 위 상황으로 인해 log data를 효율적으로 활용할 수 있게 새로운 시스템으로 이관이 필요해 진행 하였고 히스토리를 정리하려고 합니다. 2. 환경 - 데이터베이스 : MS-SQL - 개발언어 : JAVA - 도입 시스템 : AWS S3, AWS Athena, AWS Lambda, AWS SQS, AWS Glue, Java..
 로그 데이터 처리를 위한 AWS Glue 환경 구성
로그 데이터 처리를 위한 AWS Glue 환경 구성
1. AWS Glue Crawler 추가 - 클롤러 추가 버튼 클릭 합니다. - 크롤러 이름을 입력 후 다음을 버튼 클릭합니다. - 크롤러 소스 타입 : 이미 테이블을 생성했기 때문에 Existing catalog tables 선택 후 다음 버튼 클릭 - Catalog table 추가 : AWS Athena 용으로 생성한 S3 선택 후 다음 버튼 클릭 - IAM 역할 선택 : 적당한 이름 입력 후 다음 버튼을 클릭합니다. - 크롤러 일정 생성 : 일단은 테스트용이기 때문에 온디맨드로 설정하고 다음 버튼을 클릭합니다. : 추후 필요하다면 수정할 수 있습니다. - 크롤러 출력 구성 : 디폴트로 그냥 놔두고 다음 버튼을 클릭합니다. - 크롤러 정보 확인 : 입력한 크롤러 정보가 맞는지 확인 후 마침 버튼을 클..